Staigūs potvyniai yra vieni daugiausiai gyvybių nusinešusių oro sąlygų pasaulyje, kasmet nusinešę daugiau nei 5000 žmonių gyvybių. Jie taip pat yra vieni iš sunkiausiai nuspėjamų. Tačiau „Google“ mano, kad šią problemą ji išsprendė mažai tikėtinu būdu – skaitydama naujienas.
Nors žmonės surinko daug orų duomenų, staigūs potvyniai yra per trumpalaikiai ir lokalizuoti, kad būtų galima visapusiškai išmatuoti, kaip laikui bėgant stebima temperatūra ar net upių srautai. Šis duomenų trūkumas reiškia, kad gilaus mokymosi modeliai, kurie vis labiau gali prognozuoti orą, negali numatyti staigių potvynių.
Norėdami išspręsti šią problemą, „Google“ mokslininkai naudojo „Gemini“ – didžiulį „Google“ kalbos modelį – surūšiavo 5 milijonus naujienų straipsnių iš viso pasaulio, išskirdami pranešimus apie 2,6 milijono skirtingų potvynių ir paversdami tuos pranešimus geografine laiko eilute, pavadinta „Groundsource“. Pasak Gila Loike, „Google Research“ produktų vadovės, tai pirmas kartas, kai įmonė tokiam darbui naudoja kalbos modelius. Tyrimas ir duomenų rinkinys buvo viešai pasidalintas ketvirtadienio rytą.
Naudodami Groundsource kaip realaus pasaulio pradinį tašką, mokslininkai parengė modelį, pagrįstą ilgalaikės trumpalaikės atminties (LSTM) neuroniniu tinklu, kad būtų galima gauti pasaulines orų prognozes ir generuoti staigių potvynių tikimybę tam tikroje srityje.
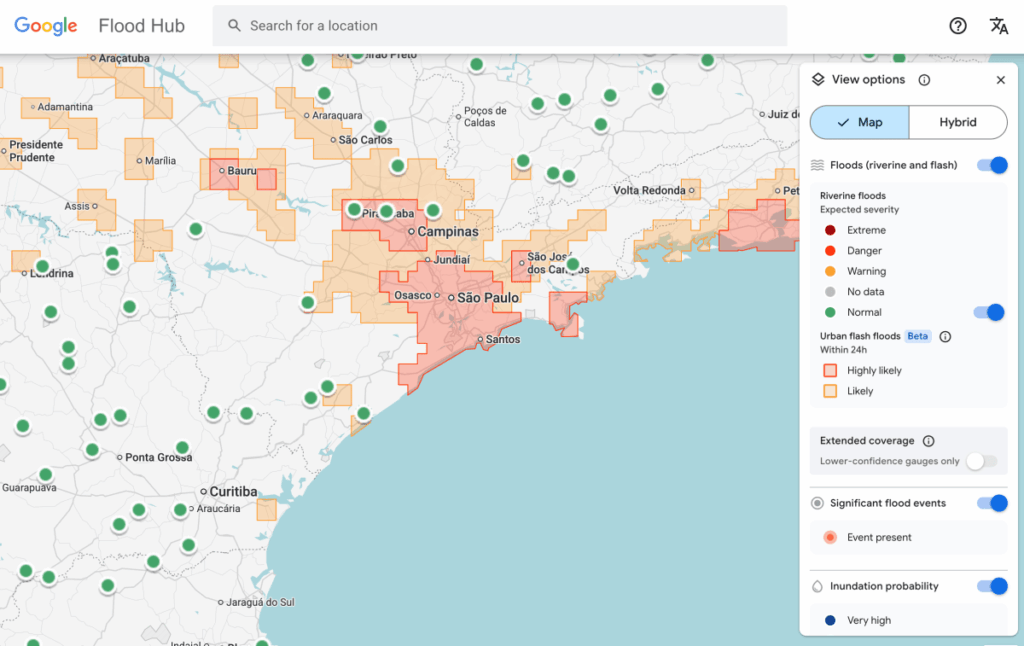
„Google“ staigių potvynių prognozavimo modelis dabar pabrėžia 150 šalių miestų teritorijoms kylančią riziką bendrovės „Flood Hub“ platformoje ir dalijasi savo duomenimis su reagavimo į nelaimes agentūromis visame pasaulyje. António José Beleza, Pietų Afrikos vystymosi bendruomenės reagavimo į ekstremalias situacijas pareigūnas, išbandęs prognozavimo modelį su Google, sakė, kad tai padėjo jo organizacijai greičiau reaguoti į potvynius.
Modeliui vis dar yra apribojimų. Pirma, tai gana maža skiriamoji geba, identifikuojanti riziką 20 kvadratinių kilometrų plotuose. Ir ji nėra tokia tiksli, kaip JAV nacionalinės orų tarnybos įspėjimo apie potvynius sistema, iš dalies todėl, kad „Google“ modelyje nėra vietinio radaro duomenų, kurie leidžia realiuoju laiku sekti kritulius.
Tačiau iš dalies ta, kad projektas buvo sukurtas dirbti ten, kur vietos valdžia negali sau leisti investuoti į brangią orų jutimo infrastruktūrą arba neturi išsamių meteorologinių duomenų įrašų.
Techcrunch renginys
San Franciskas, Kalifornija
|
2026 m. spalio 13-15 d
„Kadangi kaupiame milijonus ataskaitų, „Groundsource“ duomenų rinkinys iš tikrųjų padeda subalansuoti žemėlapį“, – šią savaitę žurnalistams sakė „Google“ atsparumo komandos programos vadovė Juliet Rothenberg. „Tai leidžia mums ekstrapoliuoti į kitus regionus, kuriuose nėra tiek daug informacijos.
Rothenbergas teigė, kad komanda tikisi, kad naudojant LLM kurti kiekybinius duomenų rinkinius iš rašytinių, kokybinių šaltinių būtų galima pritaikyti duomenų rinkiniams apie kitus trumpalaikius, bet svarbius prognozuoti reiškinius, tokius kaip karščio bangos ir purvo nuošliaužos.
Marshall Moutenot, „Upstream Tech“, bendrovės, kuri naudoja panašius giluminio mokymosi modelius upių srautams prognozuoti klientams, pvz., hidroenergijos įmonėms, generalinis direktorius, teigė, kad „Google“ indėlis yra dalis didėjančių pastangų rinkti duomenis giliu mokymusi pagrįstiems orų prognozavimo modeliams. Moutenot bendrai įkūrė dynamical.org – grupę, kuruojančią mašininiam mokymuisi paruoštų orų duomenų rinkinį tyrėjams ir pradedantiesiems.
„Duomenų trūkumas yra vienas iš sunkiausių geofizikos iššūkių“, – sakė Moutenot. „Tuo pačiu metu yra per daug Žemės duomenų, o tada, kai norite įvertinti tiesą, jų nepakanka. Tai buvo tikrai kūrybingas būdas gauti tuos duomenis.”




