
Suspaudimo kaip kokybės signalo sąvoka nėra plačiai žinoma, tačiau SEO turėtų tai žinoti. Paieškos varikliai gali naudoti tinklalapių glaudinimą, kad nustatytų pasikartojančius puslapius, įėjimo puslapius su panašiu turiniu ir puslapius su pasikartojančiais raktiniais žodžiais, todėl tai naudingos žinios SEO.
Nors toliau pateiktame moksliniame darbe rodomas sėkmingas puslapyje esančių bruožų naudojimas brukalams aptikti, dėl tyčinio paieškos sistemų skaidrumo trūkumo sunku tiksliai pasakyti, ar paieškos sistemos taiko šį ar panašius metodus.
Kas yra suspaudžiamumas?
Skaičiuojant suspaudžiamumas reiškia, kiek galima sumažinti failo (duomenų) dydį, išlaikant esminę informaciją, paprastai siekiant maksimaliai padidinti saugyklos vietą arba leisti daugiau duomenų perduoti internetu.
TL/DR suspaudimo
Suspaudimas pakeičia pasikartojančius žodžius ir frazes trumpesnėmis nuorodomis, todėl failo dydis sumažėja reikšmingomis paraštėmis. Paieškos sistemos paprastai suspaudžia indeksuotus tinklalapius, kad padidintų saugyklos vietą, sumažintų pralaidumą ir pagerintų paieškos greitį, be kitų priežasčių.
Tai supaprastintas suspaudimo veikimo paaiškinimas:
- Identifikuokite modelius:
Suspaudimo algoritmas nuskaito tekstą, kad surastų pasikartojančius žodžius, šablonus ir frazes - Trumpesni kodai užima mažiau vietos:
Kodai ir simboliai užima mažiau vietos saugykloje nei originalūs žodžiai ir frazės, todėl failo dydis yra mažesnis. - Trumpesnėse nuorodose naudojama mažiau bitų:
„Kodas“, kuris iš esmės simbolizuoja pakeistus žodžius ir frazes, naudoja mažiau duomenų nei originalai.
Papildomas glaudinimo efektas yra tas, kad jį taip pat galima naudoti norint nustatyti pasikartojančius puslapius, įėjimo puslapius su panašų turinį ir puslapius su pasikartojančiais raktiniais žodžiais.
Mokslinis darbas apie šlamšto aptikimą
Šis mokslinis darbas yra reikšmingas, nes jį parašė žymūs kompiuterių mokslininkai, žinomi dėl proveržių dirbtinio intelekto, paskirstytojo skaičiavimo, informacijos paieškos ir kitose srityse.
Marcas Najorkas
Vienas iš tyrimo straipsnio bendraautorių yra Marcas Najorkas, žymus mokslininkas, šiuo metu turintis „Google DeepMind“ išskirtinio mokslininko vardą. Jis yra TW-BERT straipsnių bendraautorius, prisidėjo prie tyrimų, skirtų padidinti netiesioginių vartotojų atsiliepimų, pvz., paspaudimų, naudojimo tikslumą, taip pat dirbo kurdamas patobulintą AI pagrįstą informacijos gavimą (DSI++: transformatoriaus atminties atnaujinimas naujais dokumentais). daug kitų svarbių proveržių informacijos paieškos srityje.
Dennisas Fetterly
Kitas bendraautoris yra Dennisas Fetterly, šiuo metu „Google“ programinės įrangos inžinierius. Jis įtrauktas į reitingavimo algoritmo, kuris naudoja nuorodas, patento bendrai išradėjas ir yra žinomas dėl savo tyrimų paskirstytojo skaičiavimo ir informacijos gavimo srityse.
Tai tik du žymūs tyrėjai, išvardyti kaip 2006 m. „Microsoft“ tyrimo dokumento apie šlamšto atpažinimą naudojant puslapio turinio funkcijas bendraautorius. Tarp kelių puslapio turinio ypatybių, kurias analizuoja moksliniai tyrimai, yra suglaudinamumas, kuris, kaip paaiškėjo, gali būti naudojamas kaip klasifikatorius, nurodantis, kad tinklalapis yra nepageidaujamas.
Šlamšto tinklalapių aptikimas naudojant turinio analizę
Nors mokslinis darbas buvo parašytas 2006 m., jo išvados išlieka aktualios ir šiandien.
Tada, kaip ir dabar, žmonės bandė reitinguoti šimtus ar tūkstančius vietomis pagrįstų tinklalapių, kurie iš esmės buvo pasikartojantis turinys, išskyrus miestų, regionų ar valstijų pavadinimus. Tada, kaip ir dabar, SEO specialistai dažnai kurdavo tinklalapius paieškos sistemoms per daug kartodami raktinius žodžius pavadinimuose, meta aprašymuose, antraštėse, vidiniame inkaro tekste ir turinyje, kad pagerintų reitingus.
Tyrimo darbo 4.6 skyriuje paaiškinama:
„Kai kurios paieškos sistemos suteikia didesnį svorį puslapiams, kuriuose kelis kartus yra užklausos raktiniai žodžiai. Pavyzdžiui, atsižvelgiant į tam tikrą užklausos terminą, puslapis, kuriame jis yra dešimt kartų, gali būti įvertintas aukščiau nei puslapis, kuriame jis pateikiamas tik vieną kartą. Siekdami pasinaudoti tokiais varikliais, kai kurie šlamšto puslapiai kelis kartus pakartoja savo turinį, bandydami užimti aukštesnį reitingą.
Tyrimo straipsnyje paaiškinama, kad paieškos sistemos suglaudina tinklalapius ir naudoja suglaudintą versiją, kad nurodytų pradinį tinklalapį. Jie pažymi, kad perteklinių žodžių kiekis padidina suspaudžiamumo lygį. Taigi jie ėmėsi bandymų, ar yra ryšys tarp aukšto lygio suspaudžiamumo ir šlamšto.
Jie rašo:
„Mūsų metodas šioje skiltyje, siekiant surasti perteklinį turinį puslapyje, yra suspausti puslapį; Siekdamos sutaupyti vietos ir disko laiko, paieškos sistemos dažnai suglaudina tinklalapius juos indeksavus, bet prieš įtraukdamos į puslapio talpyklą.
…Tinklalapių pertekliškumą matuojame pagal suspaudimo laipsnį, nesuspausto puslapio dydį padalijus iš suglaudinto puslapio dydžio. Puslapiams suspausti naudojome GZIP, greitą ir efektyvų glaudinimo algoritmą.
Didelis suspaudžiamumas atitinka šlamštą
Tyrimo rezultatai parodė, kad tinklalapiai, kurių suspaudimo koeficientas ne mažesnis kaip 4,0, dažniausiai buvo žemos kokybės tinklalapiai, šiukšlės. Tačiau didžiausias suglaudinimo lygis tapo ne toks nuoseklus, nes buvo mažiau duomenų taškų, todėl juos buvo sunkiau interpretuoti.
9 pav. Šlamšto paplitimas, palyginti su puslapio suspaudžiamumu.
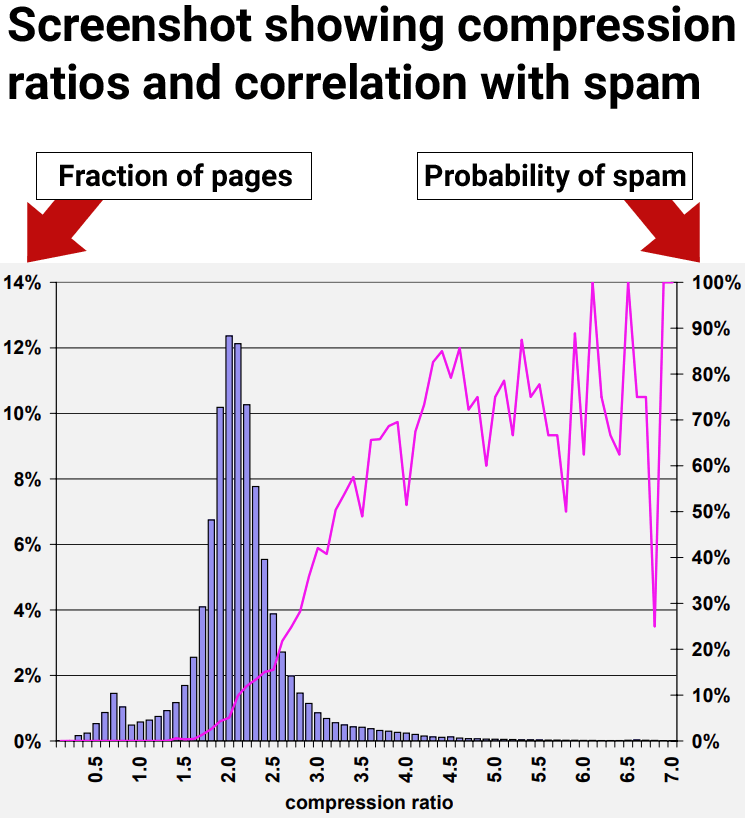
Tyrėjai padarė išvadą:
„70 % visų atrinktų puslapių, kurių glaudinimo koeficientas yra ne mažesnis kaip 4,0, buvo pripažinti kaip šlamštas.
Tačiau jie taip pat išsiaiškino, kad naudojant glaudinimo laipsnį vis tiek gaunami klaidingi teigiami rezultatai, kai puslapiai, nesusiję su šlamštu, buvo neteisingai identifikuoti kaip šlamštas:
„4.6 skirsnyje aprašyta glaudinimo koeficiento euristika pasirodė geriausiai, teisingai identifikuodama 660 (27,9 %) mūsų kolekcijos šlamšto puslapių, o klaidingai identifikavo 2 068 (12,0 %) visų įvertintų puslapių.
Naudojant visas pirmiau minėtas savybes, klasifikavimo tikslumas po dešimteriopo kryžminio patvirtinimo proceso teikia vilčių:
95,4% mūsų vertintų puslapių buvo klasifikuoti teisingai, o 4,6% buvo klasifikuoti neteisingai.
Tiksliau, 1 šlamšto klasei 940 puslapių iš 2 364 buvo klasifikuoti teisingai. Ne šlamšto klasei 14 440 puslapių iš 14 804 buvo klasifikuoti teisingai. Todėl 788 puslapiai buvo suklasifikuoti neteisingai.
Kitame skyriuje aprašomas įdomus atradimas, kaip padidinti puslapio signalų naudojimo tikslumą identifikuojant šlamštą.
Kokybės reitingų įžvalga
Tyrimo dokumente buvo nagrinėjami keli puslapyje esantys signalai, įskaitant suspaudžiamumą. Jie išsiaiškino, kad kiekvienas atskiras signalas (klasifikatorius) galėjo aptikti tam tikrą šlamštą, tačiau pasikliaujant vienu signalu, puslapiai, kurie nėra šlamštas, buvo pažymėti kaip šlamštas, kurie paprastai vadinami klaidingais teigiamais.
Tyrėjai padarė svarbų atradimą, kurį turėtų žinoti visi, besidomintys SEO, t. y. kelių klasifikatorių naudojimas padidino šlamšto aptikimo tikslumą ir sumažino klaidingų teigiamų rezultatų tikimybę. Lygiai taip pat svarbu, kad suglaudinimo signalas identifikuoja tik vieną el. pašto šiukšlių rūšį, bet ne visą šlamšto spektrą.
Svarbu tai, kad suspaudžiamumas yra geras būdas identifikuoti vienos rūšies šlamštą, tačiau yra ir kitų rūšių šlamšto, kurių šis signalas nepagauna. Kitų rūšių šlamštas nebuvo užfiksuotas suglaudinimo signalu.
Tai yra dalis, kurią turėtų žinoti kiekvienas SEO ir leidėjas:
„Ankstesnėje dalyje pristatėme daugybę euristikos, skirtos šlamšto tinklalapių analizei. Tai reiškia, kad išmatavome kelias tinklalapių charakteristikas ir nustatėme tų charakteristikų diapazonus, kurie koreliavo su puslapiu, kuris yra šlamštas. Nepaisant to, kai naudojamas atskirai, jokia technika neatskleidžia didžiosios dalies šlamšto mūsų duomenų rinkinyje, nepažymint daugelio puslapių, kurie nėra šlamštas, kaip šlamštas.
Pavyzdžiui, atsižvelgiant į 4.6 skirsnyje aprašytą suspaudimo laipsnio euristiką, vieną iš perspektyviausių metodų, vidutinė šlamšto tikimybė, kai koeficientas yra 4,2 ir didesnis, yra 72%. Tačiau tik apie 1,5 % visų puslapių patenka į šį diapazoną. Šis skaičius yra daug mažesnis už 13,8 % šlamšto puslapių, kuriuos nustatėme savo duomenų rinkinyje.
Taigi, nors suspaudžiamumas buvo vienas iš geresnių signalų, leidžiančių identifikuoti šlamštą, vis tiek nepavyko atskleisti viso šlamšto spektro duomenų rinkinyje, kurį tyrėjai naudojo signalams tikrinti.
Kelių signalų derinimas
Pirmiau pateikti rezultatai parodė, kad atskiri žemos kokybės signalai yra mažiau tikslūs. Taigi jie išbandė naudodami kelis signalus. Jie išsiaiškino, kad sujungus kelis puslapyje esančius signalus, skirtus aptikti šlamštą, buvo pasiektas geresnis tikslumas, o puslapių skaičius buvo klaidingai klasifikuojamas kaip šlamštas.
Tyrėjai paaiškino, kad išbandė kelių signalų naudojimą:
„Vienas iš būdų derinti euristinius metodus yra šiukšlių aptikimo problemą vertinti kaip klasifikavimo problemą. Šiuo atveju norime sukurti klasifikavimo modelį (arba klasifikatorių), kuris, atsižvelgiant į tinklalapį, bendrai naudotų puslapio ypatybes, kad (tikimės, teisingai) būtų suskirstytas į vieną iš dviejų klasių: šlamštas ir ne šlamštas. .
Štai jų išvados apie kelių signalų naudojimą:
„Mes ištyrėme įvairius turiniu pagrįsto šlamšto žiniatinklyje aspektus, naudodami realaus pasaulio duomenų rinkinį iš MSNSearch tikrinimo programos. Pateikėme keletą euristinių metodų, skirtų turiniu pagrįsto šlamšto aptikimui. Kai kurie mūsų šlamšto aptikimo metodai yra veiksmingesni už kitus, tačiau naudojant juos atskirai, mūsų metodai gali neidentifikuoti visų šlamšto puslapių. Dėl šios priežasties sujungėme šlamšto aptikimo metodus, kad sukurtume labai tikslų C4.5 klasifikatorių. Mūsų klasifikatorius gali teisingai identifikuoti 86,2 % visų šlamšto puslapių, o labai nedaug teisėtų puslapių pažymi kaip šlamštą.
Pagrindinė įžvalga:
Klaidingas „labai kelių teisėtų puslapių kaip šlamštas“ nustatymas buvo reikšmingas laimėjimas. Svarbi įžvalga, kurią turėtų atimti visi, susiję su SEO, yra ta, kad vienas signalas pats savaime gali sukelti klaidingus teigiamus rezultatus. Naudojant kelis signalus padidėja tikslumas.
Tai reiškia, kad atskirų reitingų ar kokybės signalų SEO testai neduos patikimų rezultatų, kuriais būtų galima pasitikėti priimant strateginius ar verslo sprendimus.
Išsinešti
Tiksliai nežinome, ar suspaudžiamumas naudojamas paieškos sistemose, tačiau tai yra paprastas naudoti signalas, kuris kartu su kitais gali būti naudojamas sugauti paprastų rūšių šlamštą, pvz., tūkstančius panašaus turinio miesto pavadinimų įėjimo puslapių. Tačiau net jei paieškos sistemos nenaudoja šio signalo, tai rodo, kaip lengva pagauti tokį manipuliavimą paieškos sistemomis ir kad šiandien paieškos varikliai gali su tuo susidoroti.
Čia yra pagrindiniai šio straipsnio punktai, kuriuos reikia atsiminti:
- Įėjimo puslapius su pasikartojančiu turiniu lengva užfiksuoti, nes jie suspaudžiami didesniu santykiu nei įprasti tinklalapiai.
- Tinklalapių grupėse, kurių glaudinimo koeficientas didesnis nei 4,0, daugiausia buvo šlamštas.
- Neigiamos kokybės signalai, naudojami siekiant sugauti šlamštą, gali sukelti klaidingus teigiamus rezultatus.
- Atlikdami šį konkretų testą, jie išsiaiškino, kad puslapyje esantys neigiamos kokybės signalai sugauna tik tam tikro tipo šlamštą.
- Kai naudojamas vienas, suglaudinimo signalas sugauna tik perteklinio tipo šlamštą, neaptinka kitų šlamšto formų ir pateikia klaidingus teigiamus rezultatus.
- Kokybiškų signalų sušukavimas pagerina šlamšto aptikimo tikslumą ir sumažina klaidingų teigiamų rezultatų skaičių.
- Šiandien paieškos sistemos turi didesnį šlamšto aptikimo tikslumą, naudojant AI, pvz., Spam Brain.
Perskaitykite mokslinį darbą, kurio nuoroda pateikiama Marco Najork „Google Scholar“ puslapyje:
Šlamšto tinklalapių aptikimas naudojant turinio analizę
Teminis vaizdas, sukurtas Shutterstock / pathdoc



